前言
好友发来的题,真难啊
题解
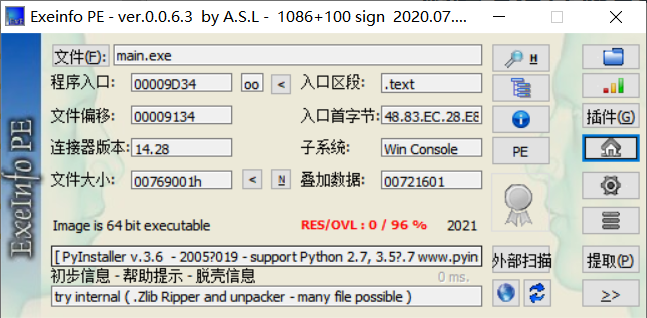
其实不用查,看图标也知道

用pyinstxtractor反编译一下,找到生成的main.pyc。
然后尝试用uncompyle6反编译pyc,会发现反编译不了python3.9字节码,一看github,rocky失业在家继续捐助才能更新支持py3.9。
但强中自有强中手,有师傅想到了其他办法。
将pyc的文件头改为
55 0D 0D 0A 01 00 00 00 4F D1 5B 87 C5 55 2F 42
这样就把这个pyc识别为python3.8
然后就能反编译了。
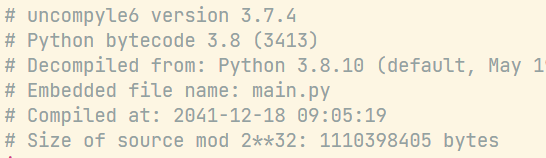
解出来代码如下:
# uncompyle6 version 3.7.4
# Python bytecode 3.8 (3413)
# Decompiled from: Python 3.8.10 (default, May 19 2021, 13:12:57) [MSC v.1916 64 bit (AMD64)]
# Embedded file name: main.py
# Compiled at: 2041-12-18 09:05:19
# Size of source mod 2**32: 1110398405 bytes
import base64
def encode(message):
s = ''
for i in message:
x = i ^ 32
x = x + 16
s += chr(x)
else:
return base64.b64encode(s.encode('utf-8'))
def enCodeAgain(string, space):
s = ''
string = str(string, 'utf-8')
for i in range(0, space):
for j in range(i, len(string), space):
if j < len(string):
s += string[j]
else:
return s
correct = 'VxVtd5dKIPjMw9wVb=lR2WVTcPWC2goWoeQ='
flag = ''
print('Input flag:')
flag = input()
flag = flag.encode('utf-8')
print(enCodeAgain(encode(flag), 2))
if enCodeAgain(encode(flag), 2) == correct:
print('correct')
else:
print('wrong')
# okay decompiling test.pycenCodeAgain()函数只是简单的跳一格取字符。
反编译不是很完全,有很多问题,其中有个小漏洞,师傅也发现了,这里只取了一半。所以需要补一下。
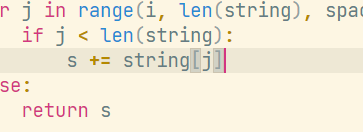
优化后的代码
import base64
def encode(message):
s = ''
for i in message:
x = (i ^ 32) + 16
s += chr(x)
return base64.b64encode(s.encode('utf-8'))
def enCodeAgain(string, space):
s = ''
a = ''
string = str(string, 'utf-8')
for j in range(0, len(string), 2):
if j < len(string):
s += string[j]
if j > 1:
a += string[j-1]
return s+a
correct = 'VxVtd5dKIPjMw9wVb=lR2WVTcPWC2goWoeQ='
flag = ''
flag = flag.encode('utf-8')
print(enCodeAgain(encode(flag), 2))逆向一下
import base64
def decode(msg):
flag = ''
s = base64.b64decode(msg.encode('utf-8')).decode('utf-8')
for i in s:
flag += chr((ord(i)-16) ^ 32)
return flag
def deCodeAgain():
a = 'VxVtd5dKIPjMw9wVb='
b = 'lR2WVTcPWC2goWoeQ='
s = ''
for i in range(0, len(a)):
s += a[i]+b[i]
return s
print(decode(deCodeAgain()))输出flag{fEncE_1s_s0_fUn}
拿回原代码执行下,输出VxVtd5dKIPjMw9wVb=lR2WVTcPWC2goWoeQ,少了个补位的=,也没差
![刷题笔记:[GXYCTF2019]BabysqliV3.0](/medias/featureimages/69.jpg)
![刷题笔记:[SWPU2019]Web4](/medias/featureimages/8.jpg)